Language: Concurrency and Parallelism
This guide covers:
- Clojure's identity/value separation
- Clojure reference types and their concurrency semantics: atoms, refs, agents, vars
- Dereferencing
- Delays, futures and promises
- Watches and validators
- How to use java.util.concurrent from Clojure
- Other approaches to concurrency available on the JVM
- Other topics related to concurrency
This work is licensed under a Creative Commons Attribution 3.0 Unported License (including images & stylesheets). The source is available on Github.
What Version of Clojure Does This Guide Cover?
This guide covers Clojure 1.12.
Before You Read This Guide
This is one of the most hardcore guides of the entire Clojure documentation project. It describes concepts that are simple but may seem foreign at first. These concepts are some of the key points of Clojure design. Understanding them may take some time for folks without a concurrent programming background. Don't let this learning curve discourage you.
If some parts are not clear, please ask for clarification
in the #clojure-doc channel on Slack
(self-signup at clojurians.net)
or file an issue on GitHub.
We will work hard on making this guide easy to follow with edits and
images to illustrate the concepts.
Introduction and Terminology
Before we get to the Clojure features related to concurrency, lets lay a foundation and briefly cover some terminology.
| Term | Definition This Guide Uses |
|---|---|
| Concurrency | When multiple threads are making progress, whether it is via time-slicing or parallelism |
| Parallelism | A condition that arises when at least two threads are executing simultaneously, e.g., on multiple cores or CPUs. |
| Shared State | When multiple threads of execution need to mutate (modify) one or more pieces of program state (e.g., variables, identities) |
| Mutable Data Structures | Data structures that, when changed, are updated "in place" |
| Immutable Data Structures | Data structures that, when changed, produce new data structures (copies), possibly with optimizations such as internal structural sharing |
| Concurrency Hazards | Conditions that occur in concurrent programs that prevent program from being correct (behaving the way its authors intended). |
| Shared Mutable State | When shared state is made of mutable data structures. A ripe ground for concurrency hazards. |
There are many concurrency hazards, some of the most common and well known are:
| Concurrency Hazard | Brief Description |
|---|---|
| Race Condition | A condition when the outcome is dependent on timing or relative ordering of events |
| Deadlock | When two or more threads are waiting on each other to finish or release a shared resource, thus waiting forever and not making any progress |
| Livelock | When two or more threads are technically performing computation but not doing any useful work (not making progress), for example, because they endlessly pass a piece of data to each other but never actually process it |
| Starvation | When a thread is not given regular access to a shared resource and cannot make progress. |
These hazards are not exclusive to threads and can happen with OS processes, runtime processes and any other execution processes. They are also not specific to a particular runtime or VM (e.g., the JVM) or programming language. Admittedly, some languages make it significantly easier to write correct, safe concurrent programs, but none are completely immune to concurrency hazards. More often than not, concurrency hazards are algorithmic problems, languages just encourage or discourage certain practices and techniques.
Thread-safe code is code that is always executed correctly and does not suffer from concurrency hazards even when executed concurrently from multiple threads.
Overview
One of Clojure design goals was to make concurrent programming easier. The thinking is that as modern CPUs add more and more cores and the number of CPUs is increasing as well, the biggest contributor to application throughput will come from making use of those resources.
The key design decision was making Clojure data structures immutable (persistent) and separating the concepts of identity and value. The importance of immutability cannot be over-emphasized: immutable values can be safely shared between threads, eliminate many concurrency hazards, and ultimately make it easier for developers to reason about their programs.
However, a language that only has immutable data structures and no way to change (mutate) program state is not very useful. The identity/value separation makes state mutations (e.g., incrementing a counter or adding an element to a list) possible in ways that have known guarantees with respect to concurrency. This separation largely eliminates the need for explicit use of locks, which is possible in Clojure but typically not necessary.
To put it another way: "changing variables" in Clojure happens differently from many other languages; in ways that are predictable from the concurrency perspective and which eliminate many concurrency hazards.
Next lets take a closer look to the identity/value separation.
Identity/Value Separation ("on State and Identity")
In Clojure, values are immutable. They never change. For example, a number is a value.
A map {:language "Clojure"} is a value. A vector with 3 elements is a value.
When you attempt to modify a value (a data structure), a new value is produced instead. These are known as persistent data structures (the word "persistent" has nothing to do with storing data on disk).
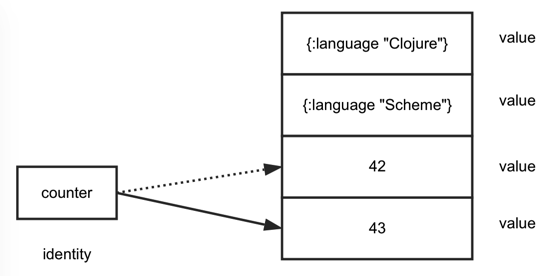
An identity is a named entity (e.g., a list of active chat group
members or a counter) that changes over time and at any given moment references a value.
For example, the current value of a counter may be 42. After incrementing it, the value
is 43 but it is still the same counter --- the same identity. This is different from, say, Java
or Ruby, where variables serve as identities that (typically) point to a mutable value
and which are modified in place.
See also Values and Change: Clojure’s approach to Identity and State on clojure.org.
Identities in Clojure can be of several types, known as reference types.
Clojure Reference Types
Overview
In Clojure's world view, concurrent operations can be roughly classified as coordinated or uncoordinated, and synchronous or asynchronous. Different reference types in Clojure have their own concurrency semantics and cover different kind of operations:
| Coordinated | Uncoordinated | |
|---|---|---|
| Synchronous | Refs | Atoms |
| Asynchronous | — | Agents |
- Coordinated
- An operation that depends on cooperation from other operations (possibly, other operations at least do not interfere with it) in order to produce correct results. For example, a banking operation that involves more than one account.
- Uncoordinated
- An operation that does not affect other operations in any way. For example, when downloading 100 Web pages concurrently, each operation does not affect the others.
- Synchronous
- When the caller's thread waits, blocks, or sleeps until it has access to a given resource or context.
- Asynchronous
- Operations that can be started or scheduled without blocking the caller's thread.
One more reference type, vars, supports dynamic scoping and thread-local storage.
Atoms
Atoms are references that change atomically (changes become immediately visible to all threads,
changes are guaranteed to be synchronized by the JVM). If you come from a Java background,
atoms are basically atomic references from java.util.concurrent with a functional twist
to them. Atoms are identities that implement synchronous, uncoordinated, atomic updates.
Lets jump right in and demonstrate how atoms work using an example. We know that Clojure data structures are immutable by default. Adding an element to a collection really produces a new collection. In such case, how does one keep a shared list (say, of active connections to a server or recently crawled URLs) and mutate it in a thread-safe manner? We will demonstrate how to accomplish this with an atom.
To create an atom, use the clojure.core/atom function. Its argument will serve as the atom's
initial value:
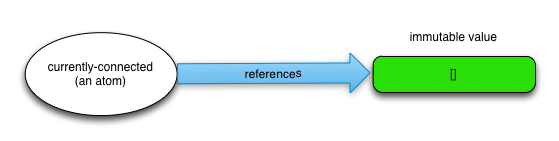
(def currently-connected (atom []))
The line above makes the atom currently-connected an empty vector. To access an atom's value, use
clojure.core/deref or the @ reader form:
(def currently-connected (atom []))
@currently-connected
;; ⇒ []
(deref currently-connected)
;; ⇒ []
currently-connected
;; ⇒ #object[clojure.lang.Atom 0x7499eac7 {:status :ready, :val []}]
As the returned values demonstrate, the atom itself is a reference. To access its current value, you dereference it. Dereferencing will be covered in more detail later in this guide. For now, it is sufficient to say that dereferencing returns the current value of an atom. (Other Clojure reference types as well as a few specialized data structures can be dereferenced as well.)
Locals can be atoms, too:
(let [xs (atom [])]
@xs)
;; ⇒ []
Now to the most interesting part: adding elements to the collection.
To mutate an atom, we can use clojure.core/swap!.
swap! takes an atom, a function and optionally some other args, swaps the current value of the atom to be the return value of calling the function with the current value of the atom and the args:
(swap! currently-connected conj "chatty-joe")
;; ⇒ ["chatty-joe"]
currently-connected
;; ⇒ #object[clojure.lang.Atom 0x7499eac7 {:status :ready, :val ["chatty-joe"]}]
@currently-connected
;; ⇒ ["chatty-joe"]
To demonstrate this graphically, initial atom state looks like this:
and then we mutated it with swap!:
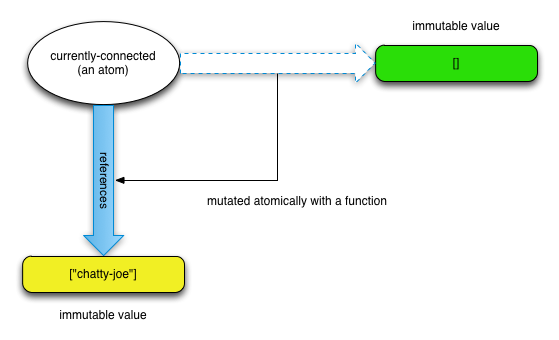
For the readers familiar with the atomic types from the java.util.concurrent.atomic package,
this should sound very familiar. The only difference is that instead of setting a value, atoms are mutated
with a function. This is both because Clojure is a functional language and because with this approach,
clojure.core/swap! can retry the operation safely. This implies that the function you provide to
swap! is pure (has no side effects).
Occasionally you will need to mutate the value of an atom the same way you would with atomic references in Java:
by setting them to a specific value. This is what clojure.core/reset! does. It takes an atom and the new value:
@currently-connected
;; ⇒ ["chatty-joe"]
(reset! currently-connected [])
;; ⇒ []
@currently-connected
;; ⇒ []
reset! may be useful in test suites to reset an atom's state between test executions, but it should be
used sparingly in your implementation code. Consider using swap! first.
By using an impure swap! function, we can see how it can retry when there
is contention:
(let [a (atom 0)
q (mapv #(future (swap! a (fn [n] (println %) (inc n))))
(range 10))]
(mapv deref q))
This will return a vector of 10 values, 1 to 10, in some arbitrary order,
and it will print the numbers 0 to 9 at least once each -- but probably
print several of them more than once, indicating that swap! was retried.
Summary and Use Cases
Atoms is the most commonly used concurrent feature in Clojure. It covers many cases and lets developers avoid explicit locking. Atoms cover a lot of use cases and are very fast. It's fair to say that when you need uncoordinated reference types (e.g., not Software Transactional Memory), the rule of thumb is, "start with an atom, then see".
It is not uncommon to initialize an atom in a local and then return it from the function and share a piece of state with other functions and/or threads.
Agents
Agents are references that are updated asynchronously: updates happen at a later, unknown point in time, in a thread pool. Agents are identities that implement uncoordinated, asynchronous updates.
A small but useful example of using an agent is as a counter. For example, suppose we want to track how often page downloads in a Web crawler respond with 40x and 50x status codes. The simplest version can look like this:
(def errors-counter (agent 0))
;; ⇒ #'user/errors-counter
errors-counter
;; ⇒ #object[clojure.lang.Agent 0x45e6d1e0 {:status :ready, :val 0}]
@errors-counter
;; ⇒ 0
(deref errors-counter)
;; ⇒ 0
One can immediately make several observations: just like atoms, agents are references. To get
the current value of an agent, we need to dereference it using clojure.core/deref or
the @agent reader macro.
To mutate an agent, we use clojure.core/send and clojure.core/send-off:
@errors-counter
;; ⇒ 0
(send errors-counter inc)
;; ⇒ #object[clojure.lang.Agent 0x45e6d1e0 {:status :ready, :val 0}]
@errors-counter
;; ⇒ 1
;; 10 is an additional parameter. The + function will be invoked as `(+ @errors-counter 10)`.
(send errors-counter + 10)
;; ⇒ #object[clojure.lang.Agent 0x45e6d1e0 {:status :ready, :val 1}]
@errors-counter
;; ⇒ 11
send and send-off are largely similar. The difference is in how they are implemented. send uses a
fixed-size thread pool so using blocking operations with it won't yield good throughput. send-off
uses a growing thread-pool so blocking operations is not a problem for it as long as there are resources
available to the JVM to create and run all the threads. On a 4-8 GB machine with 4 cores and stock
OS settings you can expect up to a couple of thousand I/O-bound threads to work without running
the system out of kernel resources.
Using Custom Executors With Agents
Agents can be used (and abused) for arbitrary code execution in a thread pool. Because the default
thread pool Clojure maintains will not be a good fit for all use cases, Clojure provides
a function that lets you control what thread pool (executor) is used by clojure.core/send:
clojure.core/set-agent-send-executor!.
(import java.util.concurrent.Executors)
(set-agent-send-executor! (Executors/newFixedThreadPool 32))
;; clojure.core/send now will use the fixed size thread pool with 32 threads
The default thread pool size is number of available CPU cores + 2.
clojure.core/set-agent-send-off-executor! is a similar function that controls what
thread pool clojure.core/send-off will use.
Finally, another useful function is clojure.core/send-via which is like
clojure.core/send but lets you specify
an executor to be used on a case-by-case basis:
(import java.util.concurrent.Executors)
(def custom-pool (Executors/newFixedThreadPool 32))
;; just like clojure.core/send but will use custom-pool instead
;; of an internally maintained one
(send-via custom-pool stream-agent inc)
Agents and Software Transactional Memory
We haven't introduced refs and the concept of Software Transactional Memory yet. It will be covered later in this guide. Here it's sufficient to mention that agents are STM-aware and can be safely used inside transactions.
Agents and Error Handling
Functions that modify an agent's state will not always return successfully in the real world. Sometimes they will fail. For example:
@errors-counter
;; ⇒ 11
(send errors-counter / 0)
;; ⇒ #object[clojure.lang.Agent 0x45e6d1e0 {:status :ready, :val 11}]
;; evaluation will produce an exception
This puts the agent into the failed state. Failed agents will re-raise the exception that caused them to fail every time their state changed is attempted:
(send errors-counter / 0)
;; Execution error (ArithmeticException) at java.util.concurrent.ThreadPoolExecutor/runWorker (ThreadPoolExecutor.java:1144).
;; Divide by zero
(send errors-counter inc)
;; Execution error (ArithmeticException) at java.util.concurrent.ThreadPoolExecutor/runWorker (ThreadPoolExecutor.java:1144).
;; Divide by zero
To access the exception that occurred during the agent's state mutation, use clojure.core/agent-error:
(send errors-counter / 0)
;; Execution error (ArithmeticException) at java.util.concurrent.ThreadPoolExecutor/runWorker (ThreadPoolExecutor.java:1144).
;; Divide by zero
(agent-error errors-counter)
;; #error {
;; :cause "Divide by zero"
;; :via
;; [{:type java.lang.ArithmeticException
;; :message "Divide by zero"
;; :at [clojure.lang.Numbers divide "Numbers.java" 190]}]
;; ...}
It returns an exception. Agents can be restarted with clojure.core/restart-agent that takes an agent
and a new initial value:
(restart-agent errors-counter 0)
;; ⇒ 0
(send errors-counter + 10)
;; ⇒ #object[clojure.lang.Agent 0x45e6d1e0 {:status :ready, :val 0}]
@errors-counter
;; ⇒ 10
If you'd prefer an agent to ignore exceptions instead of going into the failure mode, clojure.core/agent
takes an option that controls this behavior: :error-mode. Because completely ignoring errors is rarely a good
idea, when the error mode is set to :continue you must also pass an error handler function:
(def errors-counter (agent 0
:error-mode :continue
:error-handler (fn [failed-agent exception]
(println (ex-message exception)))))
;; ⇒ #'user/errors-counter
(send errors-counter inc)
;; ⇒ #object[clojure.lang.Agent 0x25a94b55 {:status :ready, :val 0}]
(send errors-counter inc)
;; ⇒ #object[clojure.lang.Agent 0x25a94b55 {:status :ready, :val 1}]
(send errors-counter / 0)
;; output: Divide by zero
;; => #object[clojure.lang.Agent 0x25a94b55 {:status :ready, :val 2}]
(send errors-counter inc)
;; ⇒ #object[clojure.lang.Agent 0x25a94b55 {:status :ready, :val 2}]
@errors-counter
;; ⇒ 3
The handler function takes two arguments: an agent and the exception that occurred.
You can also change the error mode and error handler programmatically, using
clojure.core/set-error-mode! and clojure.core/set-error-handler!.
Summary and Use Cases
Agents are asynchronously updated references. They can be used for anything that does not require strict consistency for reads:
- Counters (e.g. message rates in event processing)
- Collections (e.g. recently processed events)
Agents can be used for offloading arbitrary computations to a thread pool, and they can provide the same flexibility as JDK executors (thread pools).
Refs
Refs are the only coordinated reference type Clojure has. They help ensure that multiple identities can be modified concurrently within a transaction:
- Either all refs are modified or none are
- No race conditions between involved refs
- No possibility of deadlocks between involved refs
Refs provide ACI of ACID. Refs are backed by Clojure's implementation of software transactional memory (STM).
To instantiate a ref, use the clojure.core/ref function:
(def account-a (ref 0))
;; ⇒ #'user/account-a
(def account-b (ref 0))
;; ⇒ #'user/account-b
Like atoms and agents covered earlier, to get the current value of a ref, use clojure.core/deref or the "@"
reader macro:
(deref account-a)
;; ⇒ 0
@account-b
;; ⇒ 0
Refs are for coordinated concurrent operations and so it does not make much sense to use a single ref
(in that case, an atom would be sufficient). Refs are modified in a transaction in the clojure.core/dosync
body.
clojure.core/dosync starts a transaction, performs all modifications and commits changes. If a concurrently
running transaction modifies a ref in the current transaction before the current transaction commits,
the current transaction will be retried to make sure that the most recent value of the modified
ref is used.
TBD: a picture that visualizes retries and serializability.
alter
Refs are modified using clojure.core/alter which is very similar to
clojure.core/swap! in the arguments it takes: a ref, a function that
takes an old value and returns a new value of the ref, and any number
of optional arguments to pass to the function.
In the following example, two refs are initialized at 1000, representing two bank accounts. Then 100 units are transferred from one account to the other, atomically:
(def account-a (ref 1000))
;; ⇒ #'user/account-a
(def account-b (ref 1000))
;; ⇒ #'user/account-b
(dosync
;; will be executed as (+ @account-a 100)
(alter account-a + 100)
;; will be executed as (- @account-b 100)
(alter account-b - 100))
;; ⇒ 900
@account-a
;; ⇒ 1100
@account-b
;; ⇒ 900
Conflicts and Retries
TBD: explain transaction conflicts, demonstrate transaction retries
commute
With a high number of concurrently running transactions, retries
overhead can become noticeable. Some modifications, however, can be
applied in any order. Clojure's STM implementation acknowledges this
fact and provides an alternative way to modify refs:
clojure.core/commute. commute must only be used for operations
that commute in the mathematical
sense:
the order can be changed without affecting the result. For example,
addition is commutative (1 + 10 produces the same result as 10 + 1)
but subtraction is not (1 − 10 does not equal 10 − 1).
clojure.core/commute has the same signature as clojure.core/alter:
@account-a
;; ⇒ 1100
@account-b
;; ⇒ 900
(dosync
(commute account-a + 300)
(commute account-b + 300))
;; ⇒ 1200
@account-a
;; ⇒ 1400
@account-b
;; ⇒ 1200
Note that a change made to a ref by commute will never cause a transaction
to retry. commute does not cause transaction conflicts.
Using Refs With Clojure Data Structures
TBD: demonstrate more complex changes, e.g., to game characters
Limitations of Refs
Software transactional memory is a powerful but highly specialized tool. Because transactions can be retried, you must only use pure functions with STM. I/O operations cannot be undone by the runtime and very often are not idempotent.
Structuring your application code as a pure core with edge code that interacts with the user or other services (performing I/O operations and other side-effects) helps with this. In that case, the pure core can use STM without issues. This is often referred to as functional core, imperative shell.
For example, in a Web or network server, incoming requests are the edge code: they do I/O. The pure core is then called to modify server state, do any calculations necessary, return a result that is returned back to the client by the edge code:
TBD: a picture to demonstrate
Unlike some other languages and runtimes (for example, Haskell), Clojure will not prevent you from
doing I/O in transactions. It is left as a matter of discipline on the programmer's part. It does provide
a helper function, though: clojure.core/io! will raise an exception if there is an STM transaction
running and has no effect otherwise.
First, an example with pure code:
(io!
;; pure code, clojure.core/io! has no effect
(reduce + (range 0 100)))
;; ⇒ 4950
And an example that invokes functions that are guarded with clojure.core/io! in an STM
transaction:
(defn render-results
"Prints results to the standard output"
[]
(io!
(println "Results:")
(comment ...)))
;; ⇒ #'user/render-results
(dosync
(alter account-a + 100)
(alter account-b - 100)
(render-results))
;; throws java.lang.IllegalStateException, "I/O in transaction!"
Summary and Use Cases
TBD
Vars
Vars are the reference type you are already familiar with. You define them via the def special form:
(def url "https://en.wikipedia.org/wiki/Margarita")
Functions defined via defn are also stored in vars. Vars can be dynamically scoped. They have
root bindings that are initially visible to all threads. When defining a var
with def, you define a var that only has root binding, so its value will be the same no matter
what thread you use it from:
(def url "https://en.wikipedia.org/wiki/Margarita")
;; ⇒ #'user/url
(.start (Thread. (fn []
(println (format "url is %s" url)))))
;; outputs "url is https://en.wikipedia.org/wiki/Margarita"
;; ⇒ nil
(.start (Thread. (fn []
(println (format "url is %s" url)))))
;; outputs "url is https://en.wikipedia.org/wiki/Margarita"
;; ⇒ nil
Dynamic Scoping and Thread-local Bindings
To temporarily change var value, we need to make the var dynamic by adding :dynamic true to its
metadata and then use clojure.core/binding:
(def ^:dynamic *url* "https://en.wikipedia.org/wiki/Margarita")
;; ⇒ #'user/*url*
(println (format "*url* is now %s" *url*))
;; outputs "*url* is now https://en.wikipedia.org/wiki/Margarita"
(binding [*url* "https://en.wikipedia.org/wiki/Cointreau"]
(println (format "*url* is now %s" *url*)))
;; outputs "*url* is now https://en.wikipedia.org/wiki/Cointreau"
;; ⇒ nil
Note that, by convention, vars which are supposed to or may be dynamically scoped are named with leading
and trailing asterisks * (often referred to as "earmuffs").
In the example above, binding temporarily changed the var's current value to a different URL. But that happened only
in the same thread as the var was originally defined in. What makes vars interesting from the concurrency
point of view is that their bindings can be thread-local (yes, if you are familiar with thread-local variables
in Java or Ruby, it is very similar and serves largely the same purpose). To demonstrate, let's change
the example to spin up 3 threads and alter the var's value from them:
(def ^:dynamic *url* "https://en.wikipedia.org/wiki/Margarita")
;; ⇒ #'user/*url*
(println (format "*url* is now %s" *url*))
;; outputs "*url* is now https://en.wikipedia.org/wiki/Margarita"
;; ⇒ nil
(.start (Thread. (fn []
(binding [*url* "https://en.wikipedia.org/wiki/Cointreau"]
(println (format "*url* is now %s" *url*))))))
;; outputs "*url* is now https://en.wikipedia.org/wiki/Cointreau"
;; ⇒ nil
(.start (Thread. (fn []
(binding [*url* "https://en.wikipedia.org/wiki/Guignolet"]
(println (format "*url* is now %s" *url*))))))
;; outputs "*url* is now https://en.wikipedia.org/wiki/Guignolet"
;; ⇒ nil
(.start (Thread. (fn []
(binding [*url* "https://en.wikipedia.org/wiki/Apéritif"]
(println (format "*url* is now %s" *url*))))))
;; outputs "*url* is now https://en.wikipedia.org/wiki/Apéritif"
;; ⇒ nil
(println (format "*url* is now %s" *url*))
;; outputs "*url* is now https://en.wikipedia.org/wiki/Margarita"
;; ⇒ nil
As you can see, var scoping in different threads did not modify the var's value in the thread it was originally defined in (its root binding). In real-world cases, for example, it means that a multi-threaded Web crawler can store some crawling state specific to a particular thread in a var and not modify its initial (global) value.
How to Alter Var Root
Sometimes, however, modifying the root binding is necessary. This is done via clojure.core/alter-var-root
which takes a var (not its value) and a function that takes the old var value and returns a new one:
*url*
;; ⇒ "https://en.wikipedia.org/wiki/Margarita"
(.start (Thread. (fn []
(alter-var-root (var user/*url*) (fn [_] "https://en.wikipedia.org/wiki/Apéritif"))
(println (format "*url* is now %s" *url*)))))
;; outputs "*url* is now https://en.wikipedia.org/wiki/Apéritif"
;; ⇒ nil
*url*
;; ⇒ "https://en.wikipedia.org/wiki/Apéritif"
clojure.core/var is used to locate the var (user/*url* in our example executed in the REPL). Note that it
finds the var itself (the reference, the "box"), not its value (what the var evaluates to).
You can also use the reader macro #' to get a var: #'user/*url* which is a little less typing.
In the example above the function we use to alter var root ignores the current value and simply returns a predefined string:
(fn [_] "https://en.wikipedia.org/wiki/Apéritif")
Such functions are common enough for clojure.core to provide a convenience higher-order function called
clojure.core/constantly. It takes a value and returns a function that, when executed, ignores all its parameters
and returns that value. So, the function above would be more idiomatically written as
*url*
;; ⇒ "https://en.wikipedia.org/wiki/Margarita"
(.start (Thread. (fn []
(alter-var-root #'user/*url* (constantly "https://en.wikipedia.org/wiki/Apéritif"))
(println (format "*url* is now %s" *url*)))))
;; outputs "*url* is now https://en.wikipedia.org/wiki/Apéritif"
;; ⇒ nil
*url*
;; ⇒ "https://en.wikipedia.org/wiki/Apéritif"
When is alter-var-root used in real world scenarios? Mostly for working in
the REPL where you want some system state in a global var to be easily accessible but its value
would normally be computed locally inside a function (such as -main when
an application starts up).
Summary and Use Cases
To summarize: vars can have dynamic scope. They have a root binding and can have thread-local bindings as well.
As such, vars are good for storing pieces of program state that vary between threads but cannot
be stored in a function local. alter-var-root is used to alter root binding of a var. It is done
the functional way: by providing a function that takes the old var value and returns a new one.
To alter var root to a specific known value, use clojure.core/constantly.
Dereferencing
Earlier sections demonstrated the concept of dereferencing. Dereferencing means retrieving the current
value of a reference (an atom, an agent, a ref, etc). To dereference a Clojure reference, use
clojure.core/deref or the @reference reader macro:
(let [xs (atom [])]
@xs)
;; ⇒ []
Besides atoms, agents, and refs, Clojure has several other concurrency-oriented data structures that can be dereferenced: delays, futures, and promises. They will be covered later in this guide.
Dereferencing Support For Data Types Implemented In Java
Clojure identifies data types that can be dereferenced by checking whether they implement
the clojure.lang.IDeref interface. If that interface is not implemented, deref
assumes the data type will implement java.util.concurrent.Future and calls
.get on it.
It is possible to make custom data types implemented in Java support dereferencing by
making them implement the clojure.lang.IDeref interface:
package clojure.lang;
public interface IDeref{
Object deref();
}
This can be done to make data types implemented in Java look and feel more like built-in Clojure data types, or make it possible to pass said types to a function that expects its arguments to be dereferenceable.
Dereferencing Support for Data Types Implemented in Clojure
Clojure data types can be made dereferenceable by implementing the clojure.lang.IDeref,
for example using reify:
(def d (reify clojure.lang.IDeref (deref [this] "I'm a value!")))
;; => #'user/d
@d
;; => "I'm a value!"
Delays
In Clojure, a delay is a data structure that is evaluated the first time it is dereferenced.
Subsequent dereferencing will use the cached value. Delays are instantiated with the clojure.core/delay
function.
In the following example a delay is used to calculate a timestamp that is later used as a cached value:
(def d (delay (System/currentTimeMillis)))
;; ⇒ #'user/d
d
;; ⇒ #object[clojure.lang.Delay 0x307e4c44 {:status :pending, :val nil}]
;; dereferencing causes the value to be realized, it happens only once
@d
;; ⇒ 1696717714262
@d
;; ⇒ 1696717714262
@d
;; ⇒ 1696717714262
d
;; => #object[clojure.lang.Delay 0x307e4c44 {:status :ready, :val 1696717714262}]
clojure.core/realized? can be used to check whether a delay instance has been realized
or not:
(def d (delay (System/currentTimeMillis)))
;; ⇒ #'user/d
(realized? d)
;; ⇒ false
@d
;; ⇒ 1350997967984
(realized? d)
;; ⇒ true
Futures
A Clojure future evaluates a piece of code in another thread. To instantiate a future,
use clojure.core/future. The future function will return immediately (it never blocks
the current thread). To obtain the result of computation, dereference the future:
(def ft (future (+ 1 2 3 4 5 6)))
;; ⇒ #'user/ft
ft
;; ⇒ #object[clojure.core$future_call$reify__8544 0x70029d2d {:status :ready, :val 21}]
@ft
;; ⇒ 21
Dereferencing a future blocks the current thread. Because some operations may take a very long time or get blocked forever, futures support a timeout specified when you dereference them:
;; will block the current thread for 10 seconds, returns :completed
(def ft (future (Thread/sleep 10000) :completed))
;; ⇒ #'user/ft
(deref ft 2000 :timed-out)
;; ⇒ :timed-out
Subsequent access to futures using deref will use the cached value, just like it
does for delays.
Just like delays, it is possible to check whether a future is realized or not
with clojure.core/realized?:
(def ft (future (reduce + (range 0 10000))))
;; ⇒ #'user/ft
(realized? ft)
;; ⇒ true
@ft
;; ⇒ 49995000
Clojure futures are evaluated in an unbounded, cached thread pool that is also used by agents
(updated via clojure.core/send-off). This works well in many cases but may result in
exhaustion of the heap or thrashing if too many futures are created.
Finally, Clojure futures implement java.util.concurrent.Future and can be used with Java APIs
that accept them.
Promises
Promises are yet another take on asynchronously realized values. They are similar to futures in certain ways:
- Can be dereferenced with a timeout
- Caches the realized value
- Supported by
clojure.core/realized?
However, promises are realized not by evaluating a piece of code but by calling clojure.core/deliver
on a promise along with a value:
;; promises have no code body (no code to evaluate)
(def p (promise))
;; ⇒ #'user/p
p
;; ⇒ #object[clojure.core$promise$reify__8591 0x2a2dc0a {:status :pending, :val nil}]
(realized? p)
;; ⇒ false
;; delivering a promise makes it realized
(deliver p {:result 42})
;; ⇒ #object[clojure.core$promise$reify__8591 0x2a2dc0a {:status :ready, :val {:result 42}}]
(realized? p)
;; ⇒ true
@p
;; ⇒ {:result 42}
Promises combine many of the benefits of callback-oriented asynchronous programming and the simpler blocking function calls model provided by dereferencing.
Watches and Validators
TBD
Using Intrinsic Locks ("synchronized") in Clojure
Explicit Locking
Every object on the JVM has an intrinsic lock (also referred to as monitor lock or simply monitor). By convention, a thread that needs to modify a field of a mutable object has to acquire the object's intrinsic lock and then release it. As long as a thread owns an intrinsic lock, no other thread can acquire the same lock.
In Clojure, explicit synchronization like this is rarely necessary but may be
needed for interoperability with Java code. When you need to execute a piece
of code while holding an intrinsic lock of a mutable object, use
the clojure.core/locking macro:
(let [l (java.util.ArrayList.)]
(locking l
(.add l 10))
l)
;; ⇒ [10]
Note that for immutable Clojure data structures, explicit locking is effectively not necessary.
This section will need revisiting when Virtual Threads become more common.
Synchronization on Clojure Record Fields
TBD
Reducers (Clojure 1.5+)
- The original blog post introducing reducers
- The official
clojure.orgreference on reducers - The official API docs for the
clojure.core.reducersnamespace
java.util.concurrent
Overview
java.util.concurrent (sometimes abbreviated as j.u.c.) is a group of
concurrency utilities in the JDK. Originally introduced in JDK 5 in 2004,
they are developed and maintained by some of the experts in concurrency.
j.u.c. is a mature library that has been heavily battle tested for
almost a decade.
While Clojure provides a whole toolkit of concurrency features of its own,
in certain cases the best solution is to use an existing j.u.c. class
or even build a new abstraction on top of j.u.c. building blocks.
j.u.c. consists of multiple parts that cover common concurrent programming
patterns and use cases: from thread pools (a.k.a. executors) to synchronization
classes, to atomic variables, to concurrent collections, to the Fork/Join
framework.
Executors (Thread Pools)
Overview
The Executor interface standardizes invocation, scheduling, execution, and control of asynchronous tasks. Those tasks can be executed in the calling thread, in newly created threads, or (mostly typically) in a thread pool. Thread pools also can have different implementations: for example, be fixed size or growing dynamically, using different error handling strategies and so on.
Executors are most often instantiated using static methods of the java.util.concurrent.Executors class. To submit an operation to the pool, use the ExecutorService#submit method.
(import '[java.util.concurrent Executors ExecutorService Callable])
(let [^ExecutorService pool (Executors/newFixedThreadPool 16)
^Callable clbl (cast Callable (fn []
(reduce + (range 0 10000))))]
(.submit pool clbl))
;; ⇒ #object[java.util.concurrent.FutureTask 0x77f4c040 "java.util.concurrent.FutureTask@77f4c040[Not completed, task = user$eval5944$fn__5945@4b8137c5]"]
;; ...wait some time...
*1
;; => #object[java.util.concurrent.FutureTask 0x77f4c040 "java.util.concurrent.FutureTask@77f4c040[Completed normally]"]
@*1
49995000
In the example above, we create a new fixed size thread pool with 16 threads
and submit a Clojure function for execution. Clojure functions implement Runnable and Callable
interfaces and can be submitted for execution, however, because ExecutorService#submit
is an overloaded method, to avoid reflection warnings, we cast the function
to java.util.concurrent.Callable.
java.util.concurrent.Future
Executor#submit will return an instance of java.util.concurrent.Future. It is much like Clojure
futures but cannot be dereferenced. To get the result, use the j.u.c.Future#get method:
(import '[java.util.concurrent Executors ExecutorService Callable])
(let [^ExecutorService pool (Executors/newFixedThreadPool 16)
^Callable clbl (cast Callable (fn []
(reduce + (range 0 10000))))
task (.submit pool clbl)]
(.get task))
;; ⇒ 49995000
Scheduled Executors
TBD
Countdown Latches
Countdown latch is a thread synchronization data structure. More specifically, it handles on group of concurrent workflows: "block the current thread until N other threads are done with their work". For example, "make a POST request to N URLs and continue when all N operations succeeded or failed".
Countdown latches are instances of java.util.concurrent.CountDownLatch and instantiated with
a positive integer:
(import java.util.concurrent.CountDownLatch)
(CountDownLatch. n)
When the CountDownLatch#await method is executed, the calling thread blocks until the counter
gets to 0. Invoking the CountDownLatch#countDown method decreases the counter by 1. Count down
operations, of course, are supposed to be performed in other threads.
An example to demonstrate:
(let [cnt (atom [])
n 5
latch (java.util.concurrent.CountDownLatch. n)]
(doseq [i (range 0 n)]
(.start (Thread. (fn []
(swap! cnt conj i)
(.countDown latch)))))
(.await latch)
@cnt)
;; note the ordering: starting N threads in parallel leads to
;; non-deterministic thread interleaving
;; ⇒ [0 1 2 4 3]
In the example above, we start multiple threads and block the current thread until all other threads are done. In this example, those other threads simply add an integer to a vector stored in an atom. More realistic scenarios will contact external services, the file system, perform some computation and so on.
Because when threads are executed concurrently (or in parallel), the order of their execution is not guaranteed, we see 4 being added to the vector before 3 in the result.
Countdown latches are commonly used with initial value of 1 to "block and wait until this operation in a different thread is done".
Concurrent Collections
Most of the Java collections are mutable and were not designed for concurrency. java.util.concurrent includes a number of collections that
are thread safe and can be used for passing data structures between threads.
Atomic Variables
The java.util.concurrent.atomic package provides a number of data structures that support lock-free thread-safe programming on a single variable (identity). They support conditional atomic update operation (compared-and-swap aka CAS).
Some of the more popular atomic types in the j.u.c.atomic package are AtomicBoolean,
AtomicLong and AtomicReference.
Atomic references are pretty well covered in Clojure with atoms but occasionally may be used by other libraries. An example to demonstrate how to use an atomic long for a thread-safe counter:
(let [l (AtomicLong.)]
(dotimes [i 50]
(.start (Thread. (fn []
(.incrementAndGet l)))))
(.get l))
;; ⇒ 49
Fork/Join Framework
TBD
Other Approaches to Concurrency
There are also other approaches to concurrency that neither Clojure nor Java cover. The growing adoption of message passing concurrency (the Actor model and CSP) lead to the creation of several JVM-based frameworks for message passing. Some of the most popular ones include:
Akka's Java API can be used from Clojure either directly or via a library called Okku.
In LMAX Disruptor, event instances passed around are assumed to be mutable, so the framework is of limited use with Clojure.
Runtime Parallelism
Clojure was designed to be a hosted language. Its primary target, the JVM, provides runtime parallelism support. JVM threads map 1:1 to kernel threads. Those will be executed in parallel given that enough cores are available for OS scheduler to use.
In Clojure, many concurrency features are built on top of JVM threads and thus benefit from runtime parallelism if the program is running on a multi-core machine.
Books
Concurrency is a broad topic and it would be silly to think that we can cover it well in just one guide. To get a better understanding of the subject, one can refer to a few excellent books:
- Java Concurrency in Practice by Brian Goetz et al. is a true classic.
- Programming Concurrency on the JVM demonstrates a range of concurrency features in several JVM languages.
Wrapping Up
One of Clojure design goals was to make concurrent programming easier.
The key design decision was making Clojure data structures immutable (persistent) and separating the concepts of identity (references) and value. Immutable values eliminate many concurrency hazards, and ultimately make it easier for developers to reason about their programs.
Atoms are arguably the most commonly used reference type when working with concurrency (vars are used much more often but not for their concurrency semantics). Software Transactional Memory is a more specialized feature and has certain limitations (e.g., I/O operations must not be performed inside transactions). Finally, agents, futures, and promises provide an array of tools for working with asynchronous operations.
Concurrency is a hard fundamental problem. There is no single "best"
solution or approach to it. On the JVM, Clojure offers several
concurrency-related features of its own but also provides easy access
to the java.util.concurrent primitives and libraries such as
Akka or
Jetlang.
Contributors
Michael Klishin michael@defprotocol.org, 2012 (original author)